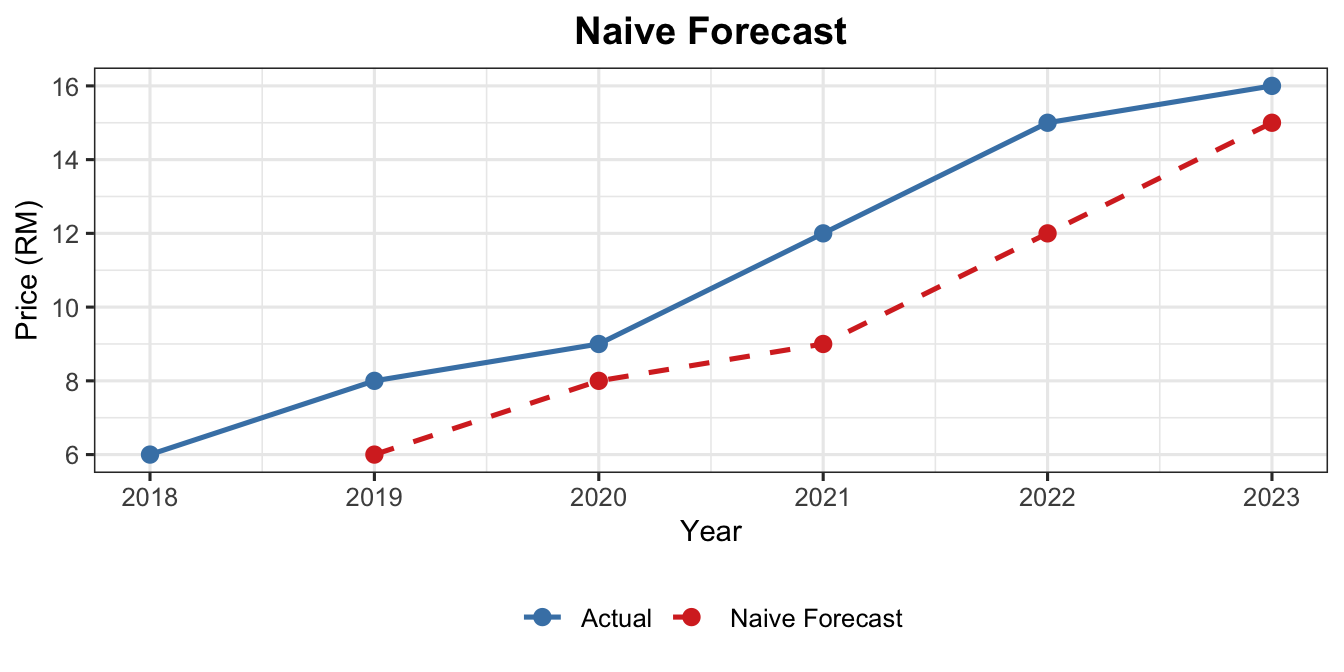
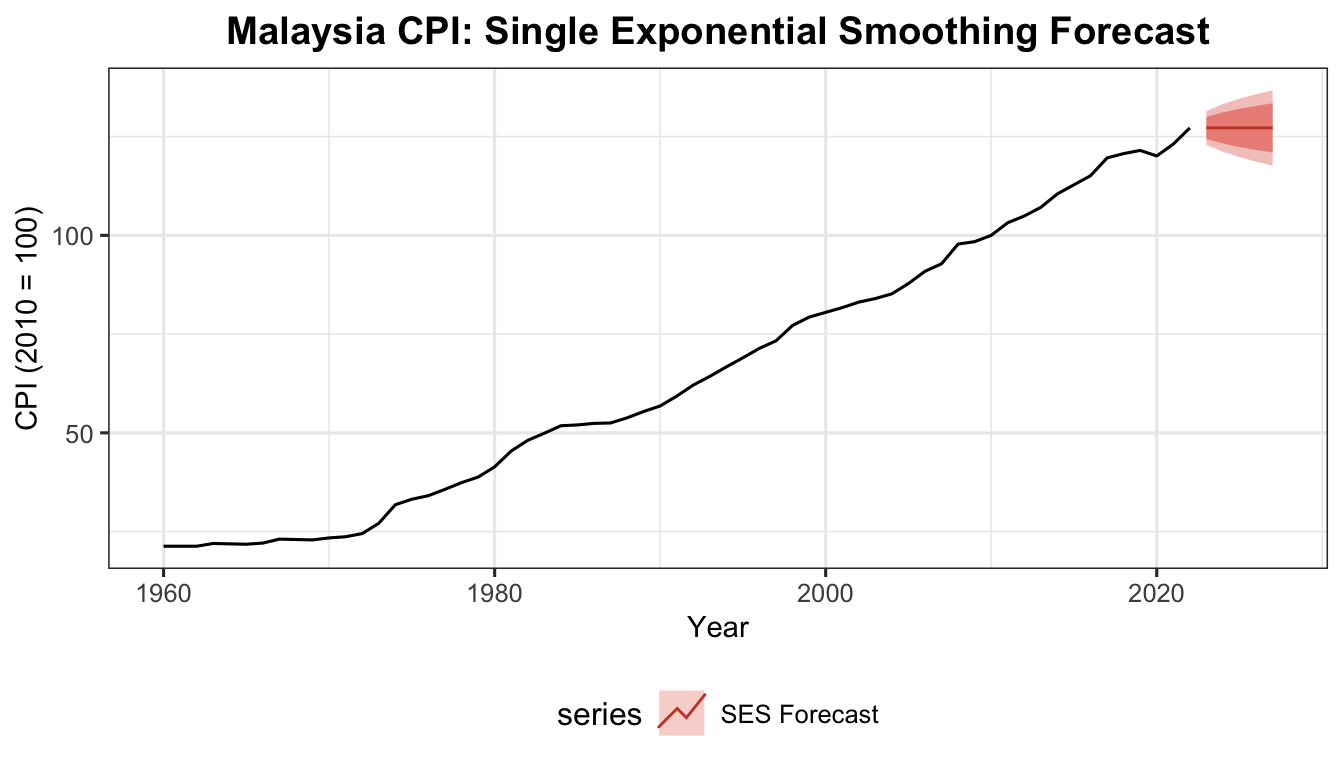
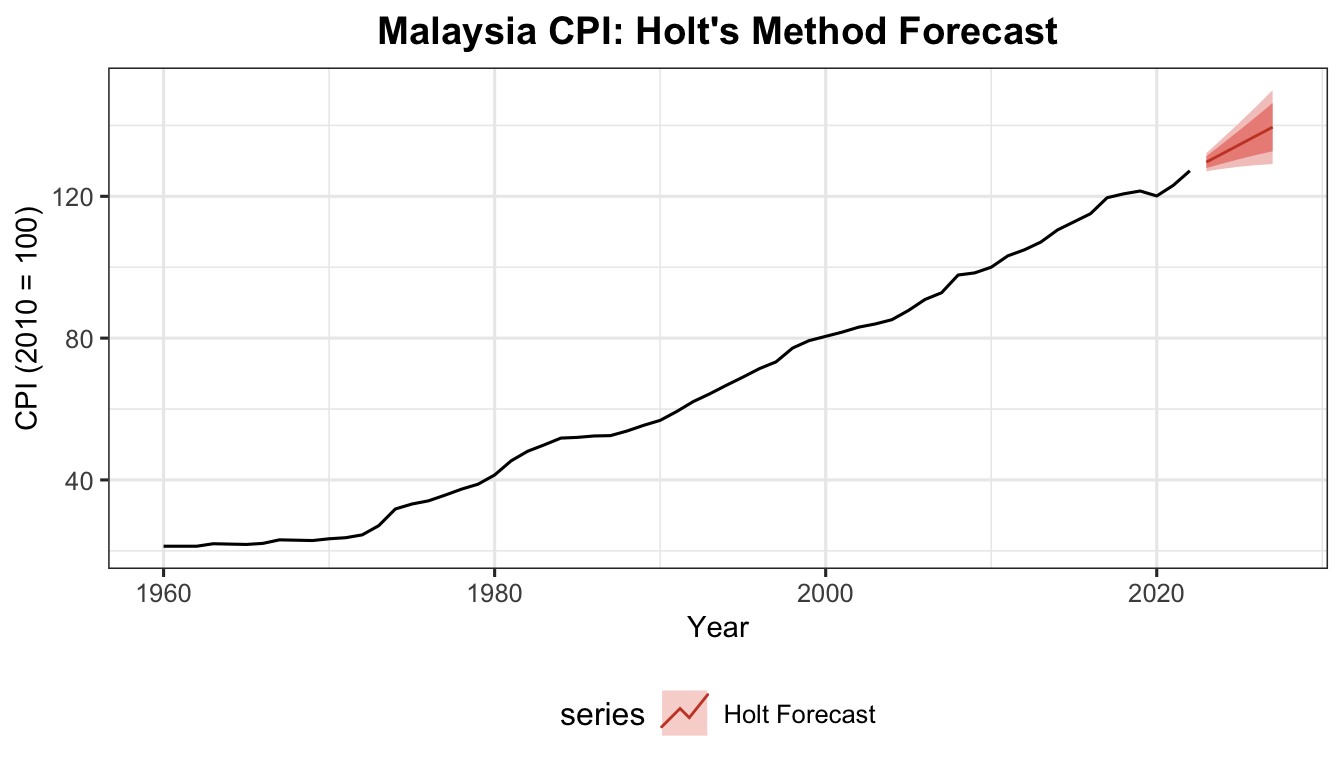
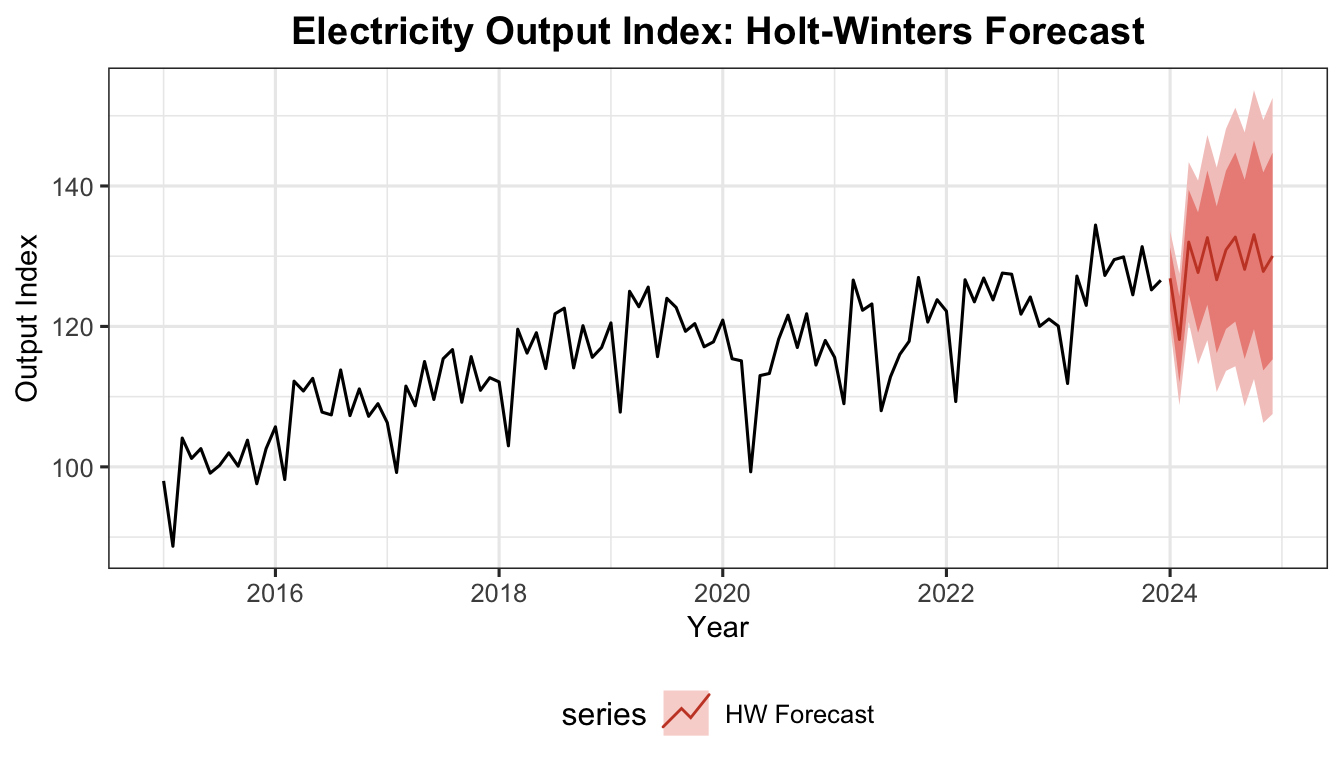
Weighted Average Interpretation — Recursive Derivation
Consider the one-step-ahead forecast:
\[F_{t+1} = \alpha y_t + (1-\alpha)F_t \tag{1}\]
Then,
\[F_t = \alpha y_{t-1} + (1-\alpha)F_{t-1} \tag{2}\]
Substitute Equation (2) into Equation (1):
\[F_{t+1} = \alpha y_t + (1-\alpha)\left[\alpha y_{t-1} + (1-\alpha)F_{t-1}\right]\]
\[F_{t+1} = \alpha y_t + \alpha(1-\alpha)y_{t-1} + (1-\alpha)^2 F_{t-1} \tag{3}\]
Let,
\[F_{t-1} = \alpha y_{t-2} + (1-\alpha)F_{t-2} \tag{4}\]
Substitute Equation (4) into Equation (3):
\[F_{t+1} = \alpha y_t + \alpha(1-\alpha)y_{t-1} + (1-\alpha)^2\left[\alpha y_{t-2} + (1-\alpha)F_{t-2}\right]\]
\[F_{t+1} = \alpha y_t + \alpha(1-\alpha)y_{t-1} + \alpha(1-\alpha)^2 y_{t-2} + (1-\alpha)^3 F_{t-2}\]
Continuing the recursive substitution for \(F_{t-2},\ F_{t-3}\) and so forth yields the final weighted average form:
\[F_{t+1} = \alpha y_t + \alpha(1-\alpha)y_{t-1} + \alpha(1-\alpha)^2 y_{t-2} + \cdots + \alpha(1-\alpha)^{t-1}y_1 + (1-\alpha)^t F_1\]
This shows that \(F_{t+1}\) is a weighted average of all past observations \(y_t, y_{t-1}, y_{t-2}, \ldots, y_1\) with respective weights:
\[\alpha,\quad \alpha(1-\alpha),\quad \alpha(1-\alpha)^2,\quad \alpha(1-\alpha)^3,\quad \ldots,\quad \alpha(1-\alpha)^{t-1},\quad (1-\alpha)^t\]
The weights decrease exponentially as we move further into the past — this is the damping effect. The most recent observation \(y_t\) provides the largest contribution; successive earlier observations provide smaller and smaller contributions.
Larger \(\alpha\) → faster damping → past observations lose influence quickly. Smaller \(\alpha\) → slower damping → past observations retain influence longer.
Example: \(\alpha = 0.8\)
The weights are \(0.8,\ 0.16,\ 0.032,\ 0.0064,\ 0.00128\) for \(y_t,\ y_{t-1},\ y_{t-2},\ y_{t-3},\ y_{t-4}\) respectively.
\[F_{t+1} = 0.8y_t + 0.16y_{t-1} + 0.032y_{t-2} + 0.0064y_{t-3} + 0.0012y_{t-4} + \cdots\]
Periods beyond \(t-3\) have almost minimal effect on the current estimate.
Example: \(\alpha = 0.2\)
The weights are \(0.2,\ 0.16,\ 0.128,\ 0.1024\) for \(y_t,\ y_{t-1},\ y_{t-2},\ y_{t-3}\) respectively.
\[F_{t+1} = 0.2y_t + 0.16y_{t-1} + 0.128y_{t-2} + 0.1024y_{t-3} + \cdots\]
The weights diminish slowly compared to a large value of \(\alpha\).
| Near 1 |
Reacts quickly; heavy weight on recent observation; fast damping |
| Near 0 |
Smooth; weights diminish slowly; more historical influence |
Comparison with 3-period Moving Average:
\[\hat{y}_2 = \frac{y_1 + y_2 + y_3}{3} = \frac{1}{3}y_1 + \frac{1}{3}y_2 + \frac{1}{3}y_3\]
The MA uses constant equal weights of \(\frac{1}{3}\) — it does not distinguish between the most recent and older observations, unlike SES.